一种基于分布式光交换的高带宽域架构InfiniteHBD
曦智科技联合北京大学、阶跃星辰为下一代万亿参数大模型训练的基础设施建设提出全新解决方案。
随着大模型参数规模的扩大,分布式训练成为人工智能发展的核心途径。分布式训练可以将模型数据分配给多个计算节点,进行并行计算和数据管理,从而显著加速模型训练的过程,而高带宽域(High Bandwidht Domain, HBD)的设计对提升模型算力利用率至关重要。
然而,现有的HBD架构在可扩展性、成本和容错能力等方面存在根本性限制:
以交换机为中心的HBD(如NVIDIA NVL72)成本高昂、不易扩展规模。
以以AI 加速器(包括GPU 与专用ASIC)为中心的HBD(如Google TPUv3和Tesla Dojo)存在严重的故障传播问题。
2022 年Google发布TPU v4 集群,首次采用光交换方案(Optical Circuit Switch,以下简称“OCS”),这种交换机-GPU混合的HBD在互连成本与系统扩展性之间采取了折中方案,但仍存在故障爆炸半径问题,其成本和容错能力仍不甚理想。
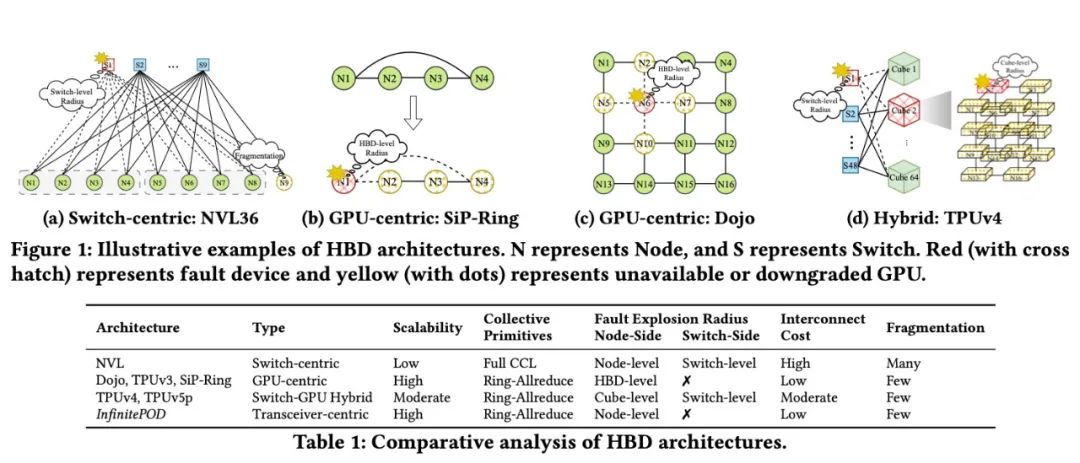
在此背景下,曦智科技联手北京大学、阶跃星辰的研究团队提出了一种以光交换(OCS)模组为中心的高带宽域架构InfiniteHBD,通过在光电转换模组中集成OCS能力,InfiniteHBD实现了动态可重构的单点对多点连接,具备节点级故障隔离和低资源碎片化的能力。
InfiniteHBD在可扩展性和成本上全面优于现有方案:InfiniteHBD的单位成本仅为NVL72的31%,GPU冗余率比NVL72和TPUv4低一个数量级,且与NVIDIA DGX(单机8卡)相比,模型算力利用率最高提升3.37 倍。
该方案以论文形式被国际通信网络领域顶级会议SIGCOMM 2025[1]接收。
曦智科技在集成硅光领域拥有十余年的产业经验,在InfiniteHBD 方案中,创新性的开发了基于硅光子技术的分布式光交换dOCS(distributed Optical Circuit Switch),将基于马赫曾德(MZI,Mach-Zehnder Interferometer)交换矩阵的光交换芯片集成到商用QSFP-DD 800Gbps光电转换模组中,大幅简化了器件结构的同时,有效提升了器件集成度,从而降低了成本和功耗,显著提升了InfiniteHBD 的性价比和系统可扩展性。
分布式光交换方案对于建设超大规模训练集群具有以下收益:
dOCS自带光电转换,提供交换能力的同时可形成跨机超节点;
光交换芯片采用成熟制程,降低了对于先进制程电交换芯片的依赖;
光交换芯片对协议不敏感,适用于当前GPU连接协议碎片化的现状
InfiniteHBD为高带宽域架构的高效扩展提供了新的解决方案,为下一代万亿参数大模型训练的基础设施建设带来了重要启示。 注释: [1]SIGCOMM,Special Interest Group on Data Communication,即数据通信专业组,是ACM(美国计算机协会)组织在通信网络领域的旗舰会议。今年的SIGCOMM 将于9 月8日-11日在葡萄牙科英布拉举行。
关于曦智科技
曦智科技是全球领先的光电混合算力提供商。公司凭借在集成光子领域的开创性技术和全球顶尖的集成电路技术研发团队,致力于在计算需求爆发的时代,为客户提供一系列算力跃迁解决方案,与客户共建更智能、更可持续的世界。曦智科技从光子矩阵计算(oMAC)、片上光网络(oNOC)和片间光网络(oNET)三大核心技术出发,打造光子计算和光子网络两大产品线,与大数据、云计算、金融、自动驾驶、生物医药、材料研究等领域客户开展紧密合作,持续为客户提供更具创造性的高效算力支撑。
- 随机文章
- 热门文章
- 无刷电机详解及其应用
- 填补中国空白,深圳传感器公司突破多个“全球第一”
- 如何实现CX变频器与PLC间的通信?
- 小鹏汽车斩获两项国际顶级安全认证 ISO 26262功能安全流程认证和ISO 21448预期功能安全(SOTIF)流程认证
- 戏剧舞台也要“节能减排”
- 【节气里的大美中国】夏至:长日炎炎,荷风送爽
- 三星艺术电视解码 “场景 × 时间 × 情感” 的三维价值需求
- 莱茵生物:三展完美收官 双奖加冕!
- 首届高等院校版画艺术展在湖北襄阳开展
- 家用充电桩全攻略:安装、成本与使用指南
- 1感染甲流后该如何科学调养?饮食起居这样做,感染甲流后该如何科学调养?饮食起居这样做
- 2马克龙去的这所大学,太宝藏了吧!,马克龙去的这所大学,太宝藏了吧!
- 3北方多地迎来降雪降温天气 各部门联动“战”寒潮筑牢安全防线,北方多地迎来降雪降温天气 各部门联动“战”寒潮筑牢安全防线
- 4“无保护”攀岩真的无保护吗?“无保护”攀岩真的无保护吗?
- 5福州发布公告:吴石故居将封闭施工,展开系统性修缮
- 6科学家的照片排在董事长之上,科学家的照片排在董事长之上
- 711月份“菜篮子”产品价格呈现季节性上涨 多因素推高生产成本,11月份“菜篮子”产品价格呈现季节性上涨 多因素推高生产成本
- 8城中话债|激活民间投资:让有效率的资本站上C位
- 9何立峰:有力有序有效做好2026年金融重点工作
- 10晚间重磅!又一万亿级券商将诞生 券业并购潮涌



